|
Beamforming Explained
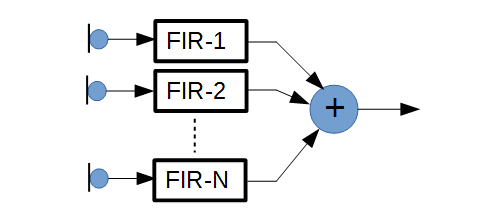
Beamforming microphone arrays are spatial filters that take multiple microphone signals
as input and combine them to a single output signal. Usually the combined output is calculated
by filtering each microphone signal through a digital FIR filter and summing the output
of all filters as shown in the figure. The figure shows a beamforming microphone array
constructed using N microphones, N FIR filters labeled FIR-1 to FIR-N and a summer.
The filters are designed so that their outputs
add constructively when sound is coming from a specific direction (main lobe)
and add destructively when sound is coming from all other directions. This creates the
spatial filtering effect of focusing at the sound that is coming from the main lobe
direction while attenuating sounds coming from all other directions.
|
|
|
Beamformer Applications
Beamformers succeeds to improve speech signal to noise ratio in many challenging situations
where other methods simply fail. One of those situations is speech recording in crowded and noisy places,
such as restaurants and bars, where many people talk and lough at the same time, making recording
the useful voice difficult. In such situation, the noise is changing fast with time, has spectral
contents similar to the useful voice, and comes from all directions around. Trying to use a
single-microphone device that employs speech recognition technology in such environment proved
to be frustrating. On the other hand, a beamformer with two or more microphones can improve
speech recognition considerably. In fact, any application that relies on microphones to record
speech can benefit the same way from beamforming microphone arrays as speech recognition does.
Beamformer Implementations
Beamforming microphone arrays may be implemented in many different ways. In its simplest
form, a beamformer may be designed to "listen" to a specific direction
(or directions) by designing the FIR filters accordingly. Alternatively, the
FIR filters may be implemented as adaptive filters that automatically "listen" to the
active user direction and automatically track the user when he/she walks around in the
room or when the active user stops talking and another user starts talking. In practice, the most common implementations fall under the following categories.
Fixed Single Main Lobe (FSML) Beamformer
In the FSML beamformer, the coefficients of each FIR filter are calculated at design
time and saved in Read Only Memory (ROM). At system initialization, the calculated
coefficients are loaded from ROM and used for filtering during real-time operation.
This makes the beamformer implementation no more complex than simple FIR filtering
which can be implemented easily on any low end DSP or CPU. Although so simple, the
FSML is very effective in many applications, such as the case of focusing on the driver position in a noisy car. Fixed Multiple Main Lobes (FMML) Beamformer
A FMML beamformer consists of several FSML. A set of spatial FIR
filters is added for each main lobe direction. The output of all filters from all lobes are
summed together, making the FMML beamformer listen to several directions at the same time. For instance, to make a beamformer listen to both the driver and passenger at the same time in the car, two FSML are used, one listens to the driver and the other to the passenger.-
360° Beamformer
The 360° beamformer is basically a FMML beamformer that covers all 360°
space. The difference is that instead of listening to several directions at the same time,
only one direction (the current active user direction) is selected.
The space around the beamformer is divided to M separate
main lobes, each lobe has resolution (360/M)° and a separate set of FIR filters is
designed for each lobe. An additional algorithm is needed to select one of the M outputs
and smoothly switch from one direction to another when the user moves around (or when
another user starts talking) to avoid any distortion in the beamformer output.
-
Adaptive Beamformer
Adaptive beamformers function similar to the 360° beamformer in that they automatically
track the user voice in the listening space. Unlike the 360° beamformers,
however, adaptive beamformers do not use M sets of beamformer filters and don't switch between
those sets of filters. Only a single set of FIR filters is used and the coefficients
of those filters are adjusted in real-time during operation
to focus on the current active user direction. The adaptation of filters
coefficients occur gradually and smoothly as in the case of switching between two sets of
filters when the direction of user voice changes.
|
Audio Examples
The performance of a beamformer depends on the number of microphones,
array shape, and spacing between the microphones. As an example, the audio samples presented below have been recorded using the OCEAN-ADSP21489-0808HC with 6-elements linear array, elements separated from each other by 5cm, and 48 kHz sampling rate.
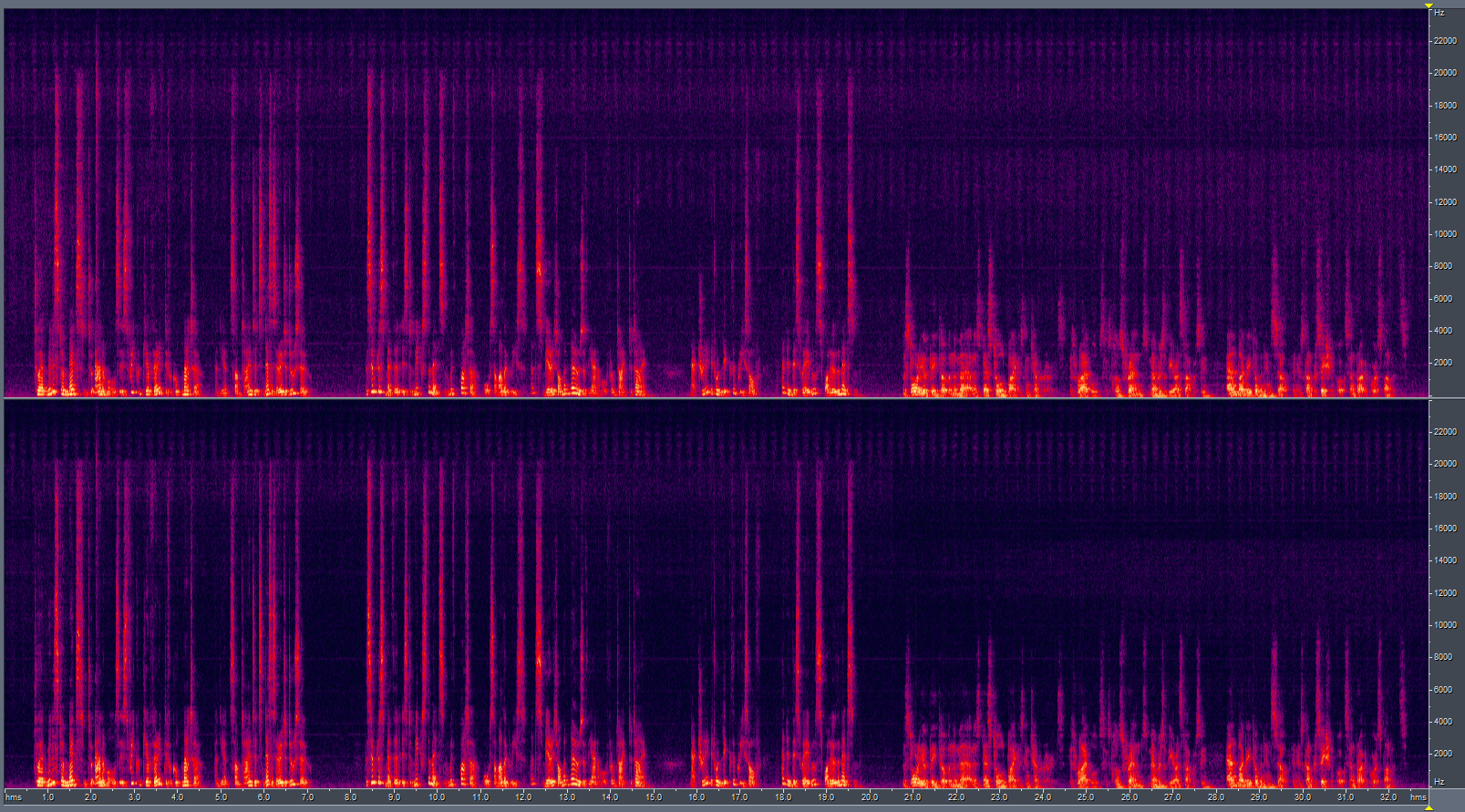
The first example below has been recorded in a quiet office. The only background noise is from normal
office environment. The second example has been recorded in the same office while music is playing
in the background. In both cases, the recording is a stereo audio file. The LEFT (top) channel is a single
microphone output and the RIGHT (bottom) channel is the beamformer output. The two channels
have been adjusted to the same loudness level for a fair comparison.
In each recording, two users have been simulated by playing audio to two different loudspeakers. One loudspeaker placed one meter directly in front of the array
played a female voice while the other loudspeaker placed two meters at 45° from the array played a male voice.
It is important to listen to the audio samples below over good quality headphones and not through loudspeakers.
Repeatedly playing one phrase while switching between LEFT and
RIGHT should show that the microphone array effectively brings the user voice to the front of the audio scene, putting
every thing else far to the background. If you listen to the two channel playing at the same time through headphones,
you should effectively hear as if the sound is coming more from the right ear although the two channels are at equal loudness.
Beamformers are also very good in improving recognition accuracy. A decrease of word error rate by an average 70% has been reported when
the microphone array output is used compared to the single microphone signal.
|
Evaluating Beamforming Microphone Arrays
Real-time demonstrators of 6, 8, and 10-element linear arrays are available on the
OCEAN-ADSP2148-0808HC and
OCEAN-ADSP2148-1204HC.
The demonstrator also includes CANEC speech enhancement and form a complete stand-alone conference appliance, high end recording device, front-end of voice recognition, and many other applications.
|
|
|
|
|